背景
基于人类反馈的强化学习,即RLHF(Reinforcement Learning from Human Feedback),是一种结合了强化学习与人类反馈的方法来优化语言模型的行为。它的核心在于利用人类对模型行为的反馈作为指导,通过强化学习的方式微调语言模型,以提升其性能和决策质量。这种方法的优势在于能够更加精细地调整模型的行为,使其更加符合人类的预期和标准。通过RLHF,可以在一定程度上解决传统机器学习方法中难以捕捉的细微差别和复杂性问题。
RLHF的过程可以分为以下几个关键步骤:
预训练语言模型:首先,需要有一个预先训练好的大语言模型(LLM)作为 base,这个模型通常是通过大量的文本数据训练得到的,以便能够理解和生成自然语言。
训练奖励模型:其次,收集问答数据集并训练一个奖励模型(Reward Model,RM)。这个奖励模型的目的是根据人类的反馈来为语言模型的行为打分,判断哪些回答是优秀的,哪些需要改进。
强化学习微调:最后,使用强化学习(RL)的方法来微调语言模型。在这个过程中,奖励模型提供的分数被用作反馈信号,指导语言模型在特定任务或行为上进行优化。
本文采用 LLaMA-Factory 作为RLHF框架。介绍 LLaMA-Factory 的环境安装和微调模型前的准备工作。
准备工作
在实验室服务器上,是没有 root 权限的,无法通过 apt 安装任何包,通过 apt list 发现当前环境连 git 都没有。因此需要先安装 conda ,然后在虚拟环境中完成接下来的所有工作。
下载 Anaconda 3
通过 wget 下载:
wget --user-agent="Mozilla" https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2024.10-1-Linux-x86_64.sh使用 wget 下载 Anaconda 报错ERROR 403 Forbidden. 原因可能是服务器正在检查引用者,一些 HTTP 请求也会得到错误响应,因为它们会拒绝不以 Mozilla 开头或不包含 Wget 的用户代理。因此需要添加 --user-agent="Mozilla" 。
下载完成后,切换到该文件目录下,运行:
bash Anaconda3-2024.10-1-Linux-x86_64.sh 
一路回车到底,输入 yes 接受协议即可,安装完成后,需要退出终端或通过 source 命令刷新环境变量:
克隆仓库代码
首先得先把 git 装好:
conda install git克隆 LLaMA-Factory 仓库代码,并进入到该目录:
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory/接下来在虚拟环境中安装 LLaMA-Factory 的依赖:
pip install -r requirements.txt值得注意的是,为了确保环境干净,推荐新建虚拟环境来安装 LLaMA-Factory 的依赖。
一定不要先安装 pytorch 后再 pip install -r requirements. txt ,网上许多教程在 pip install之前会先安装一些前置依赖,这些都不是必须的,因为 pip install 的时候会自动安装上正确的 pytorch 版本。自行安装反而会导致 pytorch 版本不符,无法启动 LLaMA-Factory。
安装完成以后,启动 webui:
注意!一定要直接在仓库根目录下 python src/webui.py。如果是先进到src文件夹,然后python webui.py,后续的操作会失败!
python src/webui.py
在浏览器输入 http://0.0.0.0:7860 即可访问 LLaMA-Factory 的 webui 界面。
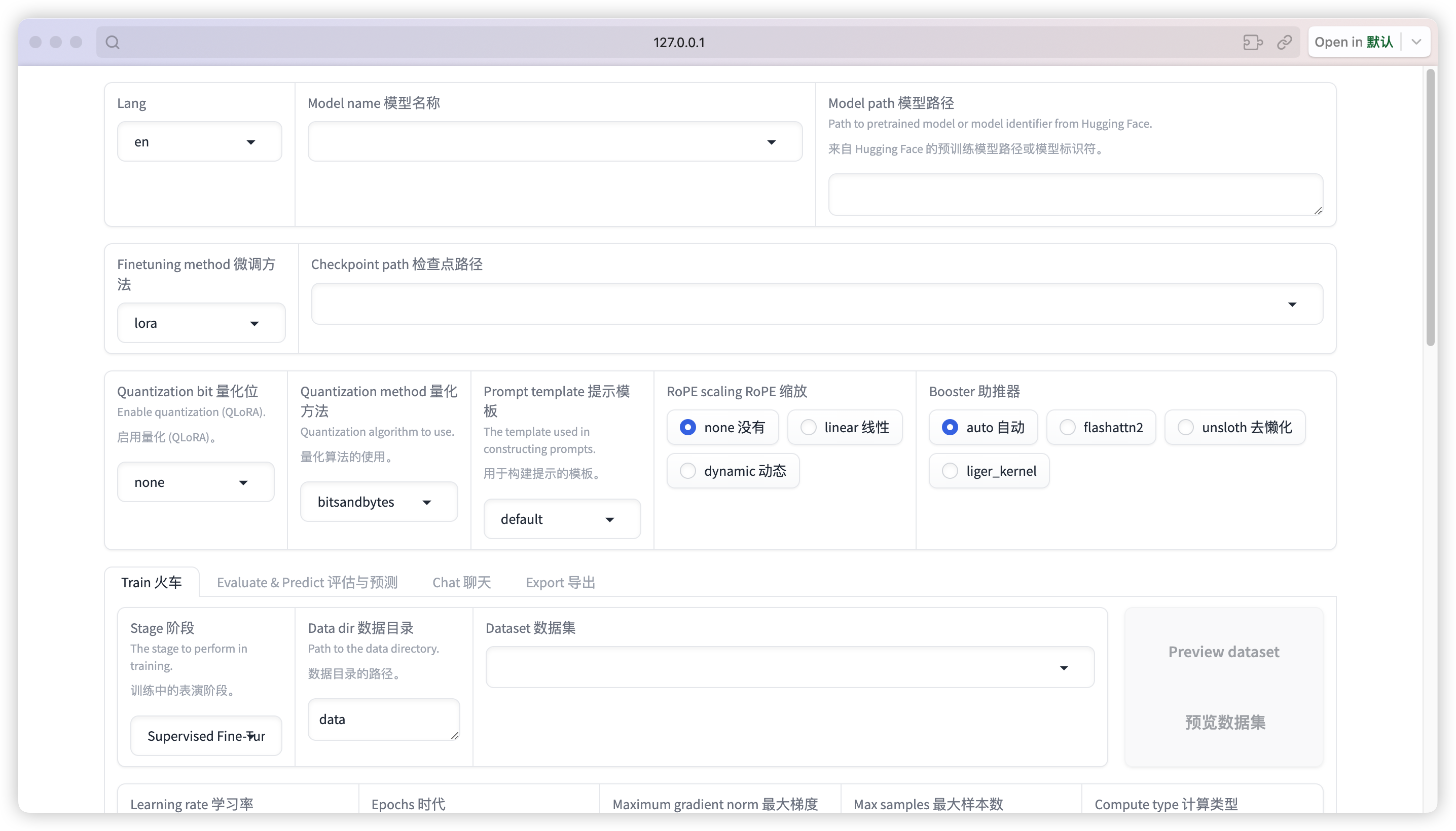
下载模型
由于是多模态任务,笔者权衡了许多模型,最后选择 Qwen2-VL-7B-Instruct 作为 model base。可以根据服务器的性能与任务需要自行选择合适的基础模型。
下载模型可以前往 Hugging Face 或者 Model Scope 按照教程下载,笔者使用的是魔搭社区(Model Scope)提供的下载方式。
先通过如下命令安装ModelScope:
pip install modelscope然后下载模型到指定文件夹(./dir 替换为指定的文件夹目录):
modelscope download --model Qwen/Qwen2-VL-7B-Instruct --local_dir ./dir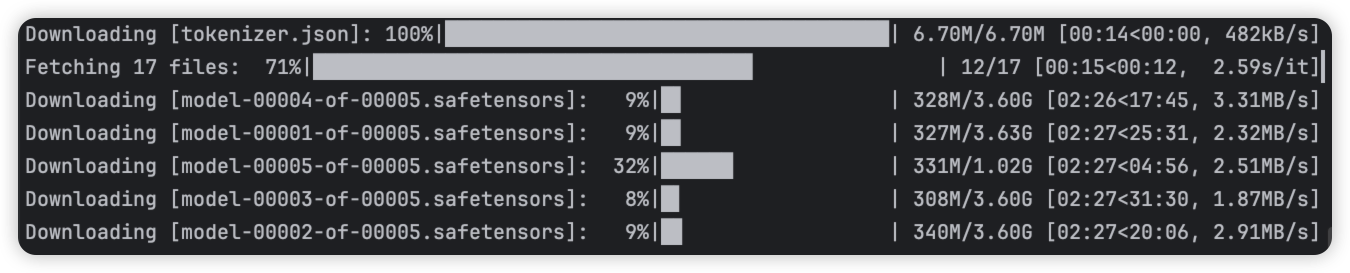
没有指定文件夹的话,模型会默认下载在 /. cache/modelscope 目录下
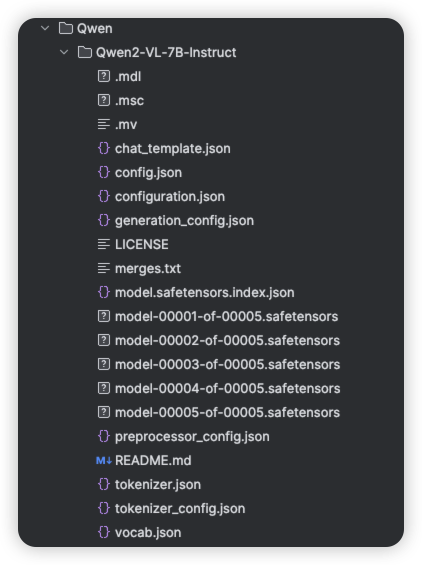
下载好的模型目录结构如下:
上传训练数据集
接下来就是准备数据集(此步骤略)上传到服务器。
微调
加载模型
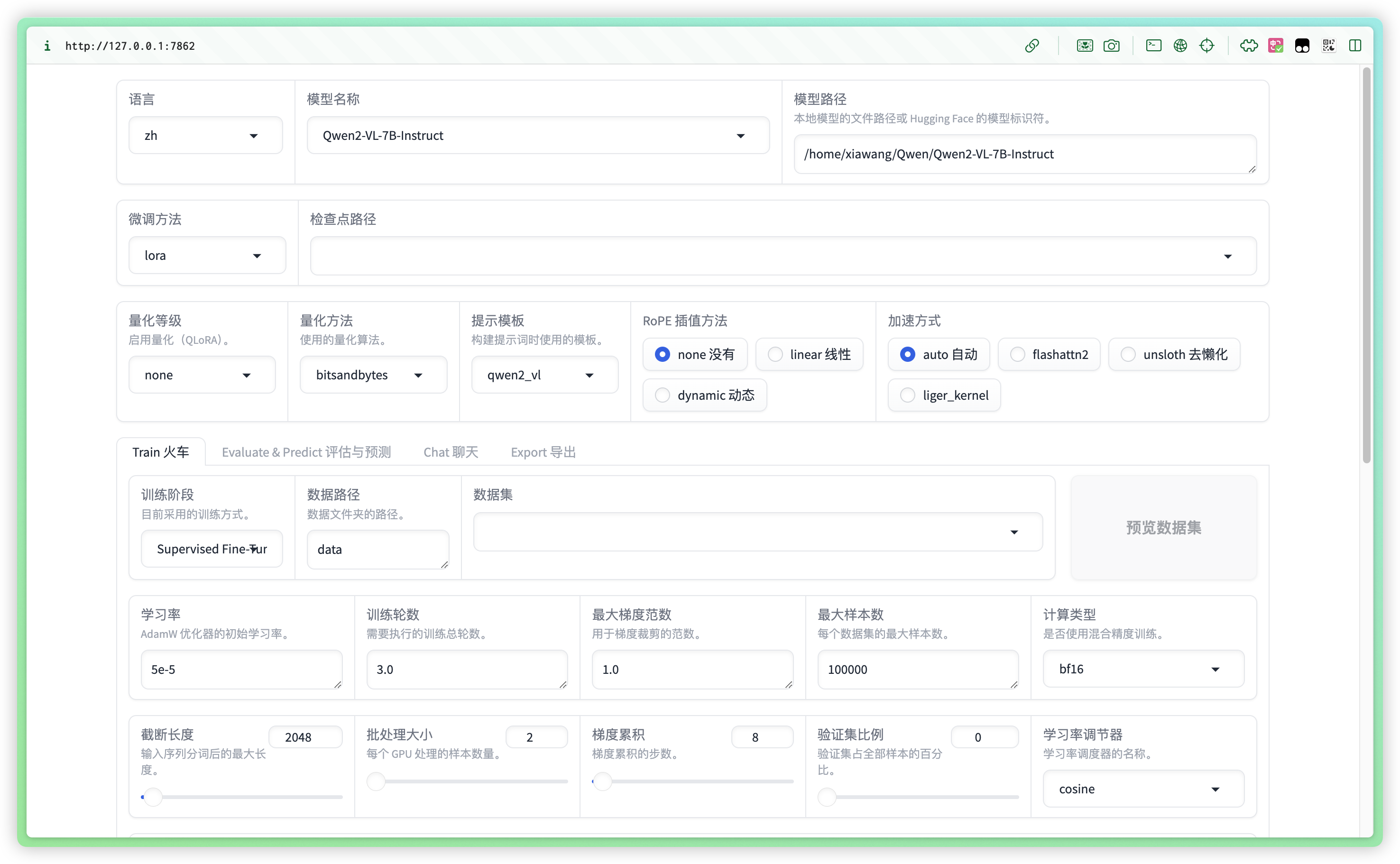
启动 LLaMA-Factory 的 webui 界面,并在顶部模型名称和模型路径中输入使用的模型的信息,其中模型路径可以使用绝对路径:
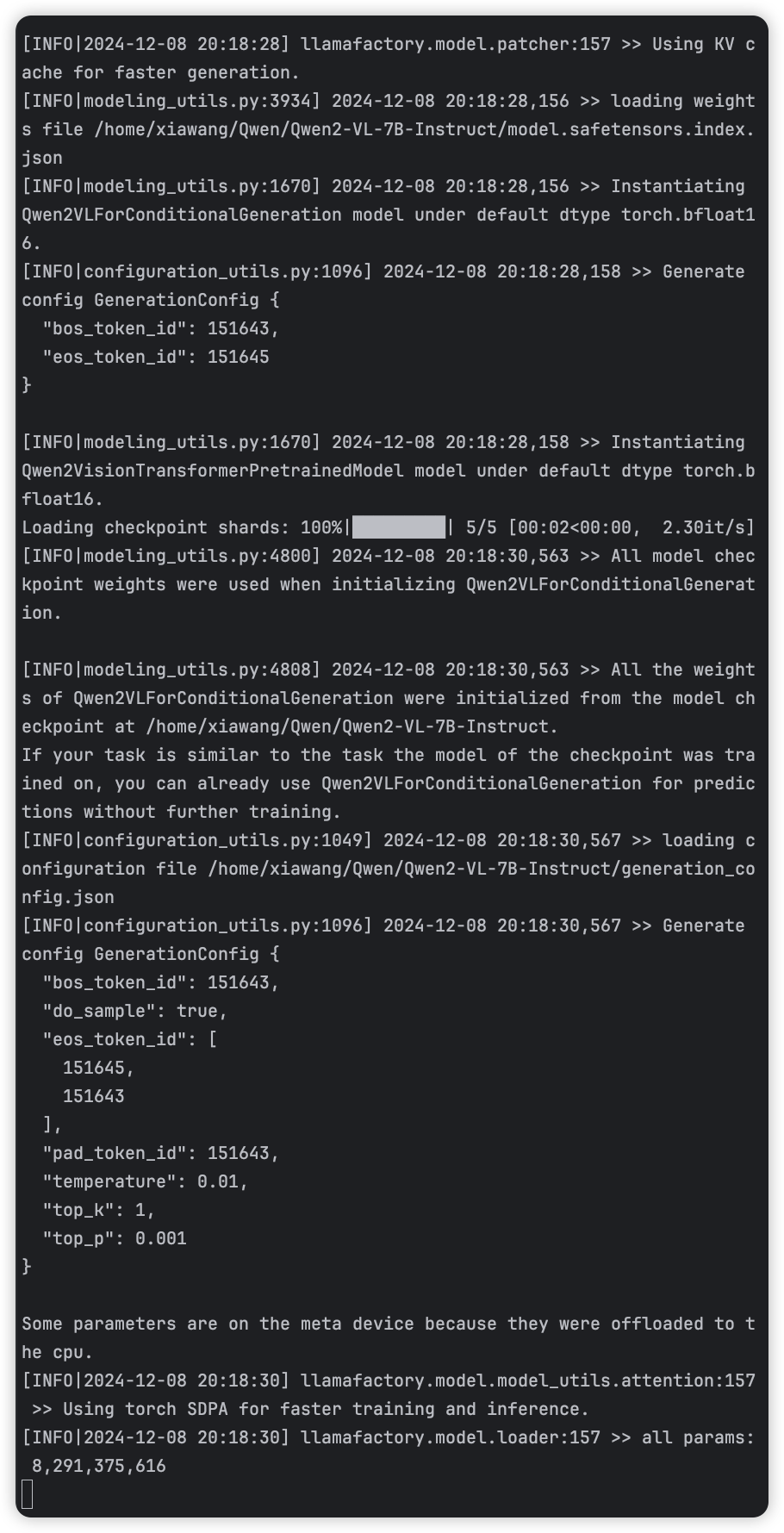
为了测试模型是否下载完整,且成功导入,点击 Chat 界面,加载模型:
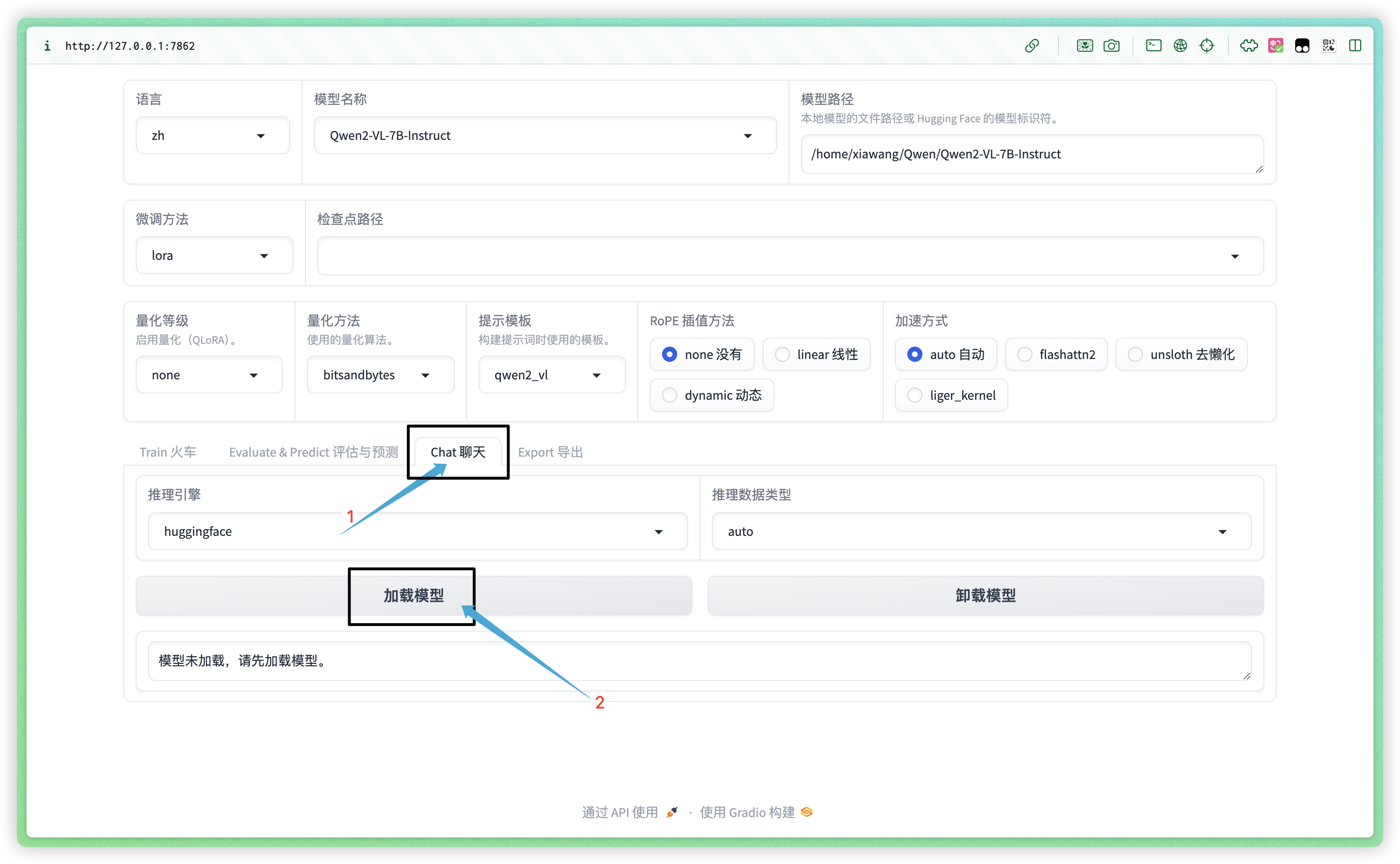
终端会加载模型,webui 会显示“模型已加载,可以开始聊天了!”:
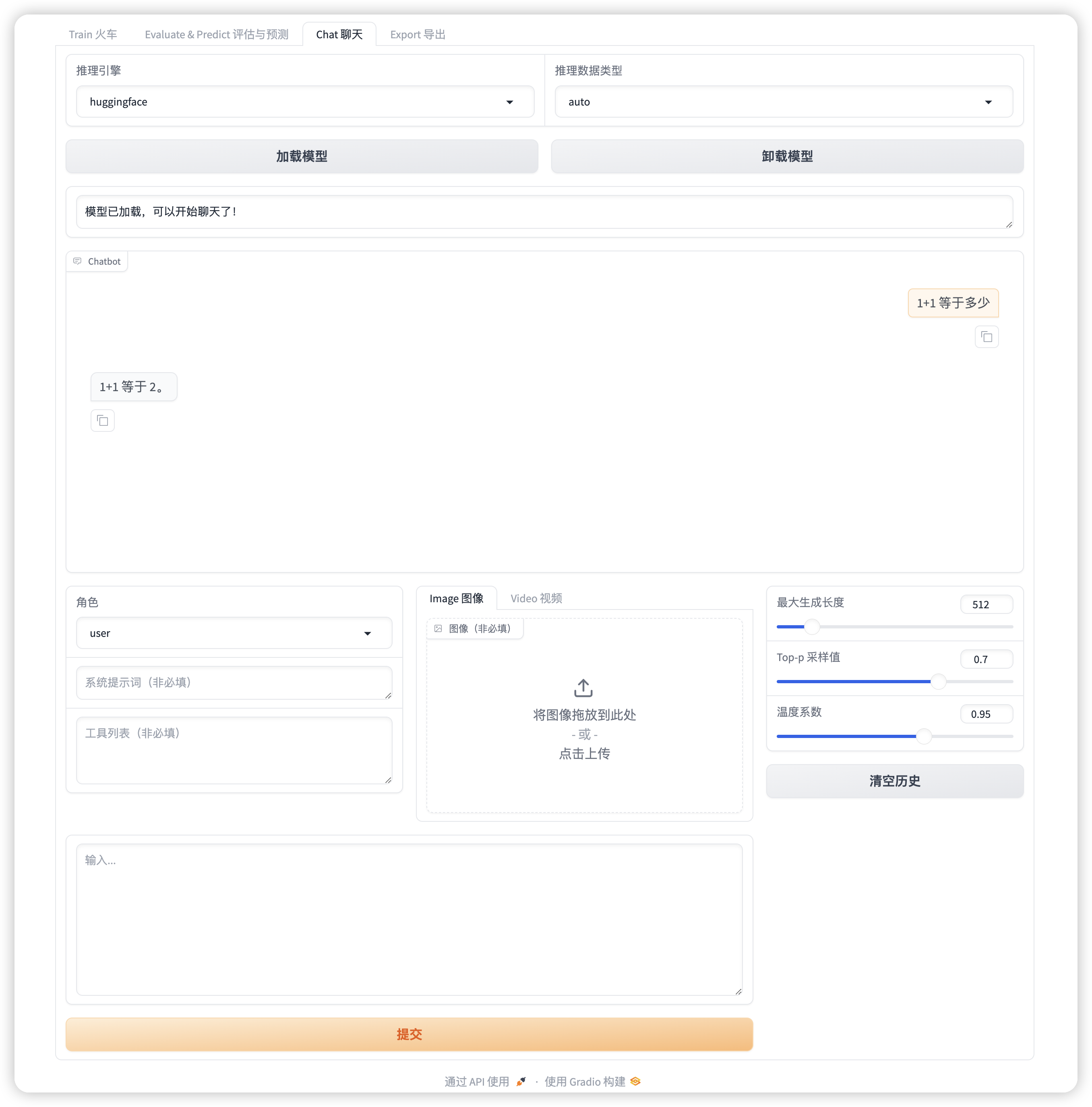
说明模型下载的是完整的,且能成功导入到 LLaMA-Factory ,那么接下来就可以开始微调模型哩!
如果加载模型时 webui 显示错误,请仔细检查终端信息的报错,可能是少装了某些依赖,终端会提示诸如 pip install vllm 的命令,安装完成后再试试加载模型。
加载数据集
数据集的路径和数据集文件名照如下方式依着瓢画葫芦即可,无须赘述:
参数设置
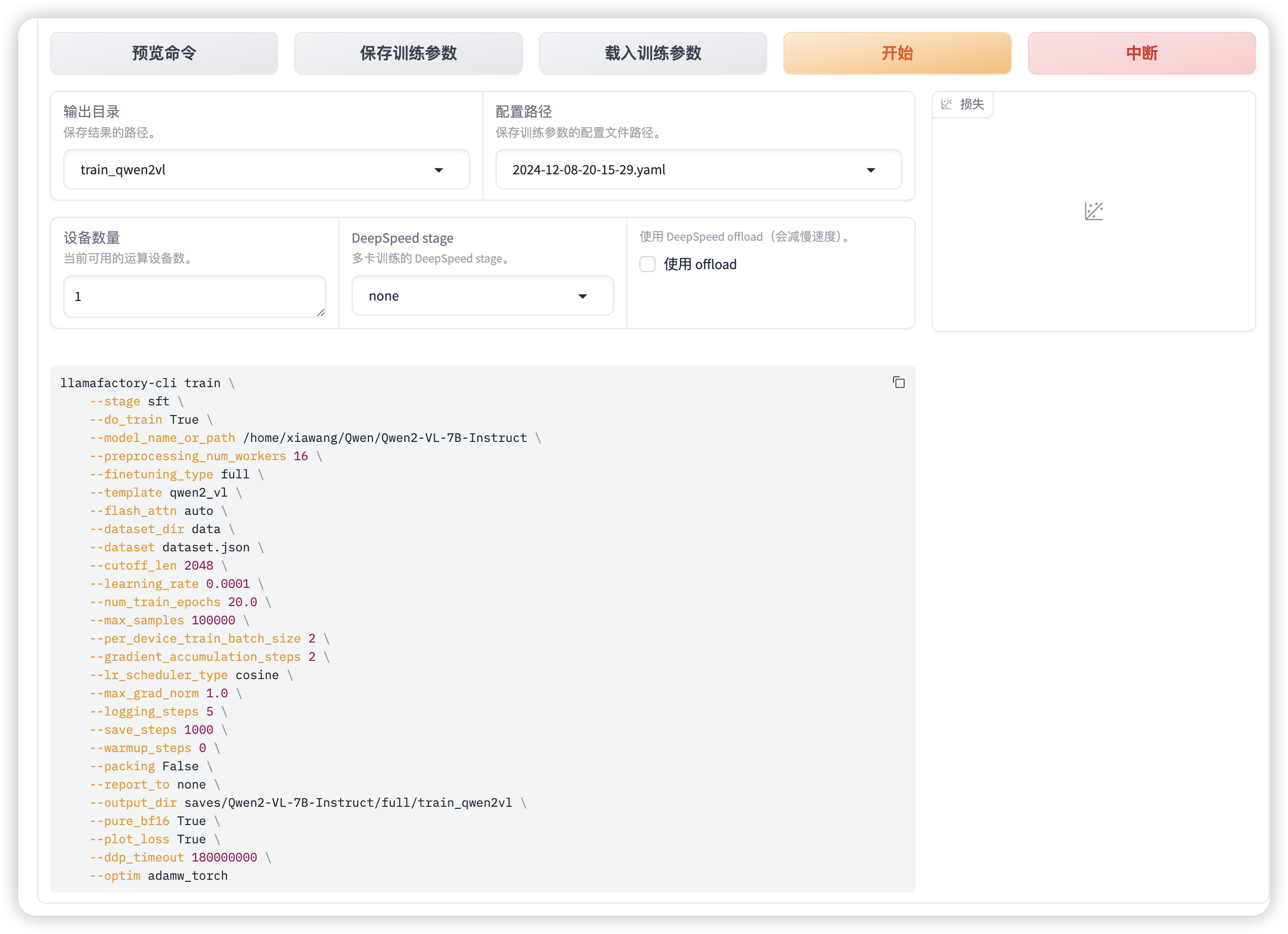
设置学习率为 1e-4,训练轮数为 10,更改计算类型为 pure_bf16,梯度累积为 2,有利于模型拟合。
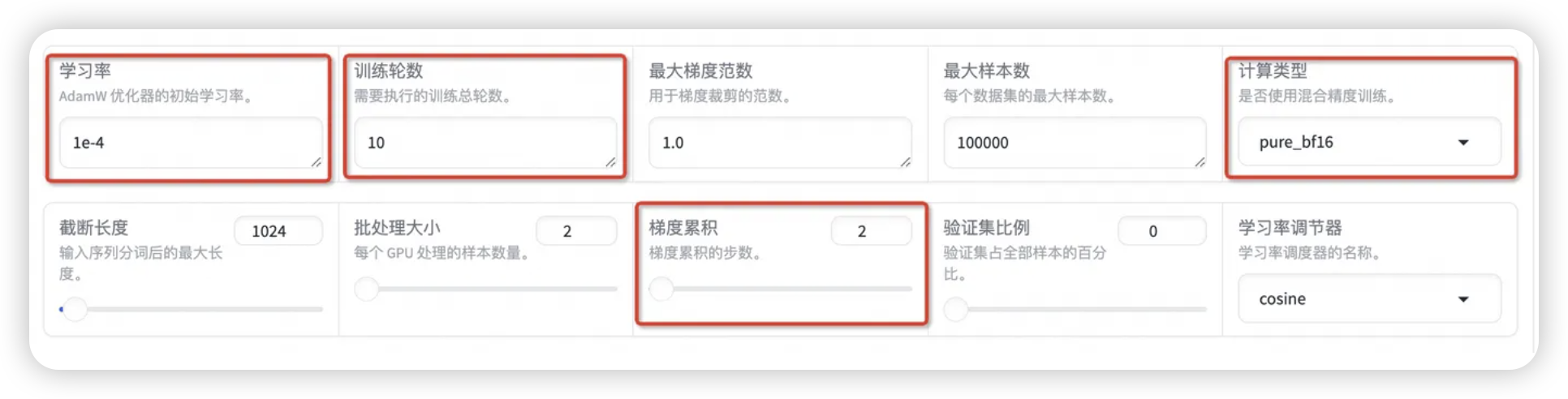
在其他参数设置区域修改保存间隔为 1000,节省硬盘空间。

启动微调
将输出目录修改为 train_qwen2vl,训练后的模型权重将会保存在此目录中。点击「预览命令」可展示所有已配置的参数,如果想通过代码运行微调,可以复制这段命令,在命令行运行。
开始!



