Binary Exploitation
二进制程序利用通过利用程序(Binary)的漏洞(Vulnerability),在执行期间控制执行流程(Control flow),进而使程序执行特定行为。
计算机组成浅析
冯诺依曼体系结构
冯.诺伊曼结构(von Neumann architecture),也称普林斯顿结构,是一种将【程序指令存储器】和【数据存储器】合并在一起的电脑设计概念结构。
在该结构中,CPU 通过地址线单向连接Memory,通过数据线双向连接 Memory。另外还有许多控制线,但是一般并不画出来。
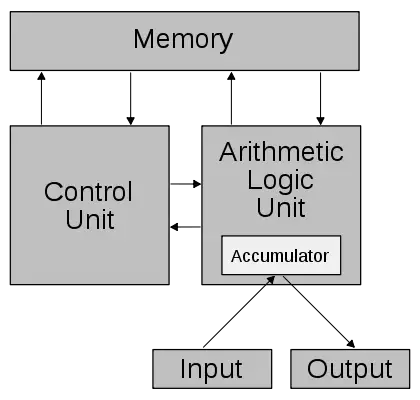
冯.诺依曼结构中,将程序和数据一样看待,将程序编码为数据,然后与数据一同存放在存储器中,这样计算机就可以调用存储器中的程序来处理数据了。意味着,无论什么程序,最终都是会转换为数据的形式存储在存储器中,要执行相应的程序只需要从存储器中依次取出指令、执行,冯.诺依曼结构的灵魂所在正是这里:减少了硬件的连接。
哈佛结构(Harvard architecture)
哈佛结构是一种将程序指令储存和数据储存分开的存储器结构。
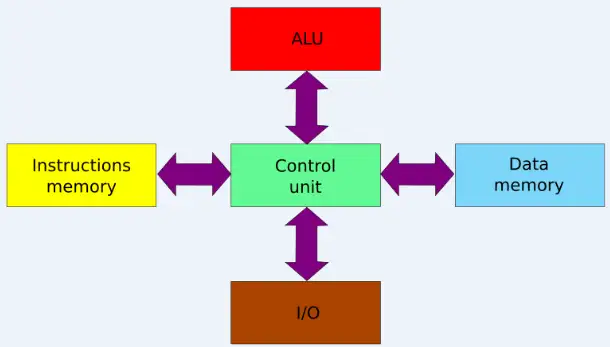
中央处理器首先到程序指令储存器中读取程序指令内容,解码后得到数据地址,再到相应的数据储存器中读取数据,并进行下一步的操作(通常是执行)。程序指令储存和数据储存分开,数据和指令的储存可以同时进行,可以使指令和数据有不同的数据宽度。
哈佛结构的微处理器通常具有较高的执行效率。其程序指令和数据指令分开组织和储存的,执行时可以预先读取下一条指令。
现在的单片机或者嵌入式机器通常采用改良的哈佛结构。
Executable and Linkable Format
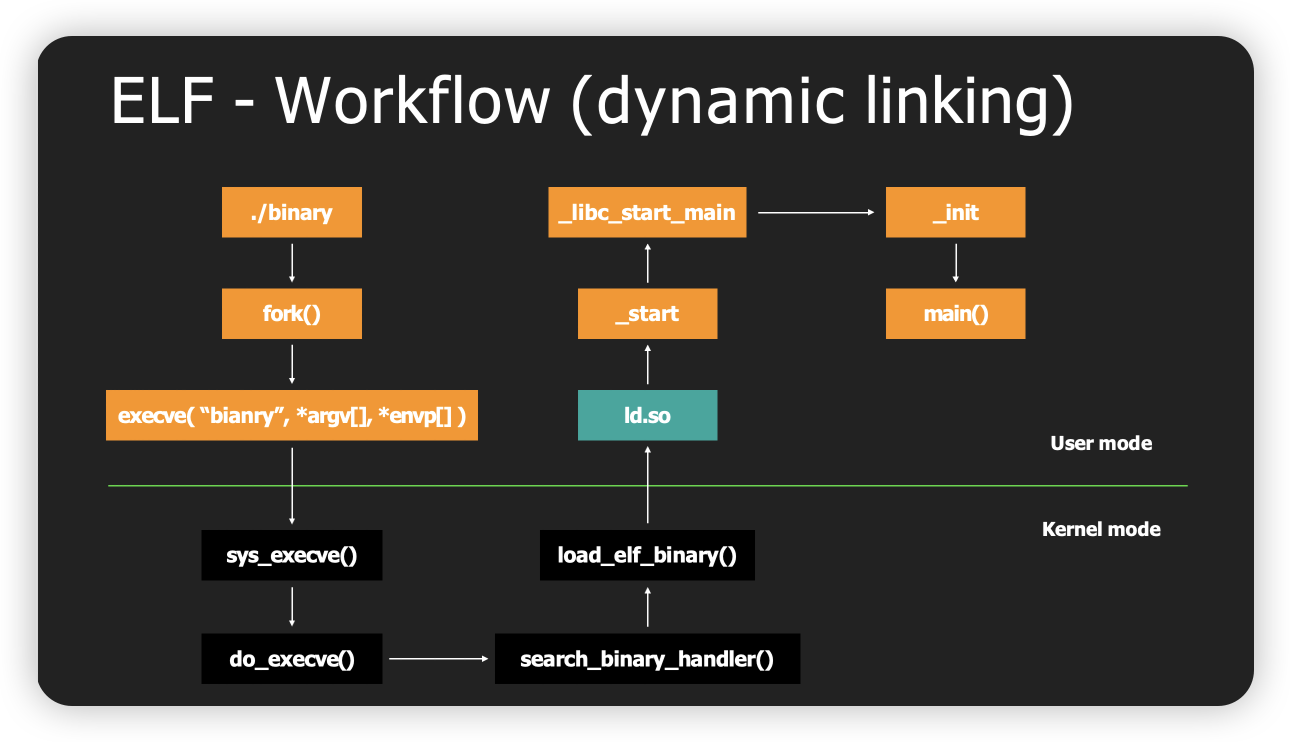

xxd ./elf | less 命令 分析二进制文件
xxd 是一个在 Unix/Linux 系统中常用的工具,用于将二进制文件转换为十六进制表示,或者反过来。在你的命令中,xxd ./elf 将 elf 文件转换为十六进制表示。
| 是 Unix/Linux 中的管道操作符,它将前一个命令的输出作为后一个命令的输入。在你的命令中,xxd ./elf | less 将 xxd ./elf 的输出作为 less 命令的输入。
less 是一个在 Unix/Linux 系统中常用的分页工具,用于查看文件内容。它允许用户向前和向后浏览文件,而 more 命令只允许向前浏览。命令xxd ./elf | less 将 elf 文件的十六进制表示分页显示。
因此,xxd ./elf | less 的整体作用是将 elf 文件转换为十六进制表示,并分页显示。
less 回显的十六进制文件中关键字的含义如下:
•RSP - Stack Pointer Register 指向 stack 顶端(头)
•RBP - Base Pointer Register 指向 stack 底端(尾)
•RIP - Program Counter Register 指向当前执行指令instruction位置
gdb
分析二进制文件调试工具
以下是使用 GDB 分析二进制文件的一般步骤:
- 启动 GDB: 你可以通过在命令行中键入
gdb <你的程序>来启动 GDB,并加载你的程序。 - 设置断点: 使用
break命令在感兴趣的代码行或函数上设置断点。 - 运行程序: 使用
run命令开始执行程序,程序会在设置的断点处停下来。 - 检查状态: 当程序在断点处停止时,你可以使用
info命令来查看变量的值、堆栈的状态等。 - 单步执行: 使用
step或next命令可以单步执行程序,区别在于step会进入函数内部,而next会在函数返回前完成函数的执行。 - 继续执行: 使用
continue命令可以从当前停止点继续执行程序,直到遇到下一个断点。 - 修改变量: 使用
set命令可以修改变量的值。 - 退出 GDB: 使用
quit命令退出 GDB。
以下是一些有用的 GDB 命令:
list: 显示源代码。print: 打印变量的值。backtrace: 显示函数调用堆栈。disassemble: 反汇编当前函数的汇编代码。x: 从内存中检查数据。
在分析二进制文件时,可能需要知道它的编译信息,例如是否包含调试符号,如果没有调试符号,可能无法获取源代码级别的信息,但仍可以查看和分析汇编级别的指令。
常见的几个汇编指令
jmp (jump): jmp 是跳转指令,用于无条件地将程序的控制权转移到指定的地址。在你的例子中,jmp A 就是将程序计数器 rip(在 64 位系统中)设置为地址 A,然后从那里开始执行。
jmp A = mov rip, Acall: call 指令用于调用子程序。它首先将下一条指令的地址(即返回地址)压入堆栈,然后跳转到指定的地址开始执行。在你的例子中,call A就是将 next_rip(即下一条指令的地址)压入堆栈,然后将 rip 设置为地址 A。
call A = push next_rip
mov rip, Aleave: leave 指令用于恢复调用者的堆栈帧。它首先将基指针 rbp 的值复制到堆栈指针 rsp,然后弹出 rbp 的值。这样就恢复了调用者的堆栈帧。
mov rsp, rbp
pop rbpret (return): ret 指令用于从子程序返回。它从堆栈中弹出一个值,然后将 rip 设置为这个值。这样,程序的控制权就返回到了调用者。
pop rip内存对齐规则和寄存器
内存对齐是为了提高内存访问效率而采取的一种策略。具体到你的问题:
- 8 bytes alignment:在 x64 架构下,数据通常以 8 字节对齐。这意味着数据的起始地址是 8 的倍数。这是因为 x64 架构的 CPU 设计为一次可以读取 8 字节的数据,如果数据没有对齐,那么可能需要多次访问内存才能读取完整的数据,这会降低效率。
- Stack 0x10 bytes alignment:对于堆栈,x64 架构要求堆栈指针
rsp在函数调用时必须是 16 字节对齐的。这是为了满足 SSE 数据类型(如xmm寄存器)的对齐要求,因为这些数据类型需要 16 字节对齐。
这些对齐规则是为了提高内存访问效率和满足特定数据类型的对齐要求。编译器和操作系统通常会自动处理这些对齐问题。
寄存器
- RAX, RBX, RCX, RDX, RDI, RSI - 这些是64位的通用寄存器。在x64架构中,它们被扩展到了64位,以’R’开头表示。这些寄存器在进行各种运算时使用,如算术运算、内存访问等。
- EAX, EBX, ECX, EDX, EDI, ESI - 这些是32位的通用寄存器。它们是x86(32位)架构中的原始寄存器,以’E’开头表示。当运行在兼容的32位模式下时,x64架构仍然使用这些寄存器。
- AX, BX, CX, DX, DI, SI - 这些是16位的寄存器,分别是上述32位寄存器的低16位部分。在历史上,这些是原始的x86 16位寄存器。
- AH, AL - 这些代表16位AX寄存器的高8位(AH)和低8位(AL)。这种细分允许对8位数据进行操作,这在处理字符和其他8位数据时非常有用。
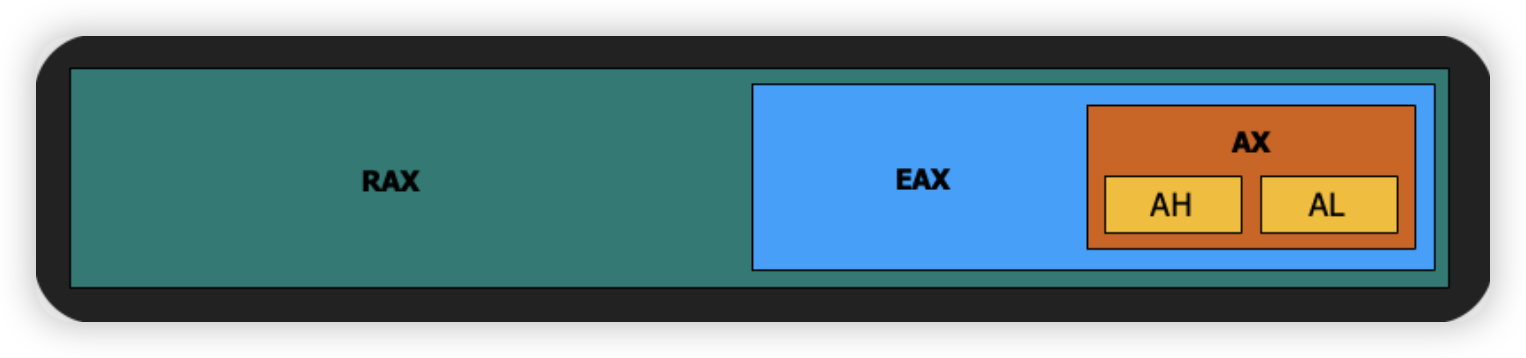
RAX 寄存器是64位的,这是最大的寄存器,它能包含EAX、AX、AH和AL。
EAX 是RAX的低32位,它是32位的。
AX 是EAX的低16位,它是16位的。进一步地,AX被分为两个8位的部分:高8位的AH和低8位的AL。
函数调用约定(calling convention)
函数调用约定定义了如何在函数调用过程中传递参数和返回值,以及如何使用寄存器。具体到 x64 架构,有以下规定:
- 参数传递:
linux下内核模式
在Linux x64架构下的内核模式,函数的参数传递与在用户模式下类似,前六个整型或指针类型的参数通过寄存器 rdi、rsi、rdx、r10(而不是用户模式下的 rcx)、r8 和 r9 传递。如果参数多于六个,额外的参数则通过堆栈传递。这些信息主要来自SysTutorials网站的相关文章。
linux 下用户模式
在 x64 架构下,前六个整型或指针类型的参数分别通过 rdi、rsi、rdx、rcx、r8 和 r9 寄存器传递。如果有更多的参数,它们将通过堆栈传递。这是与 x86 架构的一个主要区别,因为在 x86 架构下,所有的参数都是通过堆栈传递的。
window 下
Windows x64平台有自己的调用约定,前四个整型或指针类型的参数通过 rcx、rdx、r8 和 r9 寄存器传递。在Windows上,为了支持更大向量类型的参数传递,还引入了 __vectorcall 调用约定,这个约定扩展了前述的寄存器用法,允许使用 XMM/YMM0-5 寄存器来传递浮点数、向量或 HVA(Homogeneous Vector Aggregate)参数。返回值依然是通过 rax 寄存器返回的。这些调用约定的详细信息可在Wikipedia的相关页面找到。
- 返回值:在 x64 架构下,函数的返回值通过
rax寄存器返回。
Stack Frame 栈帧
它是计算机内存中的一块区域,用于存储有关函数调用和局部变量的信息。PPT在这个例子中,可以看到了一个函数func()的栈帧。
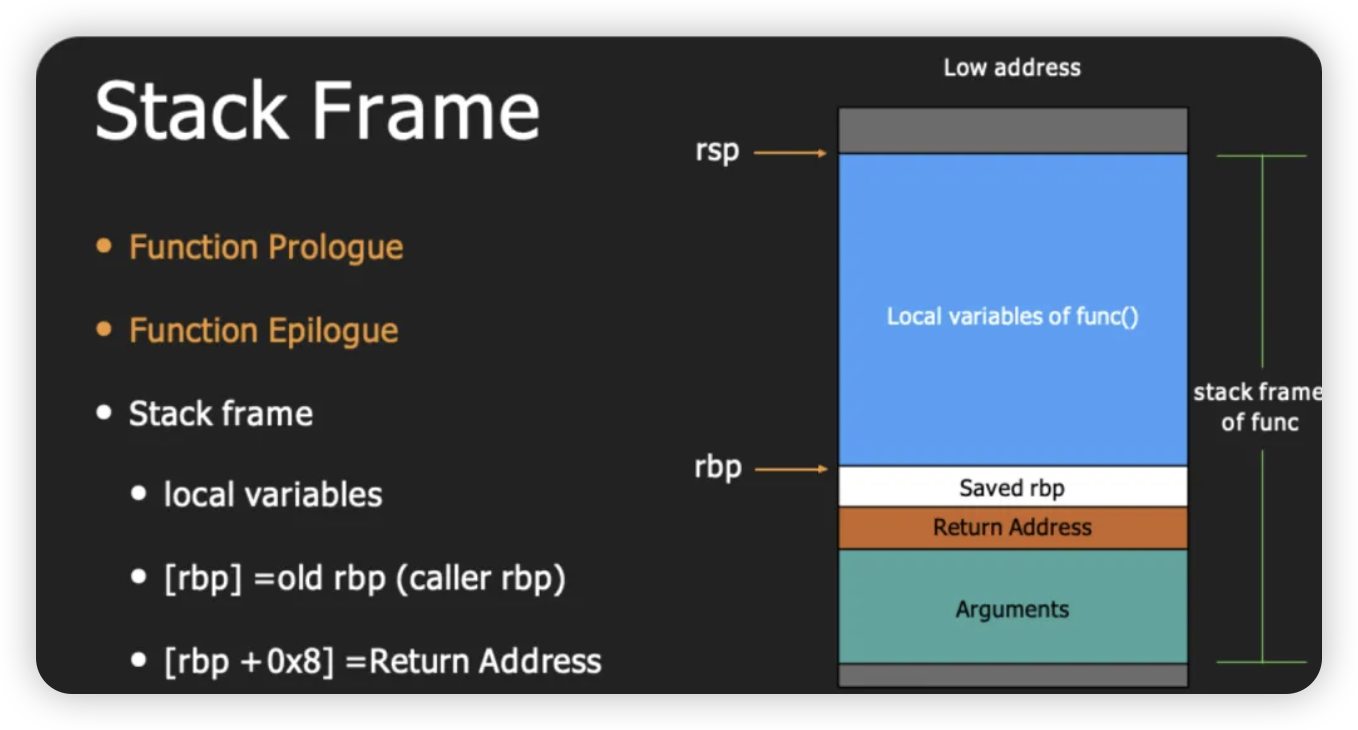
从高地址向低地址看,栈帧包含以下几个部分:
- 参数(Arguments): 当函数被调用时,传递给函数的参数在这里存储。
- 返回地址(Return Address): 这是当函数执行完毕后,程序执行需要跳转回去的地方的地址。
- 保存的rbp(Saved rbp): 这是调用函数之前的基指针(Base Pointer),也就是上一个栈帧的rbp值,用来恢复栈的状态。
- 局部变量(Local variables of func()): 这个区域用于存放函数内声明的局部变量。
在栈帧的最顶部和底部,我们看到有两个指针:
- rsp (Stack Pointer): 这指向栈的顶部,通常表示当前栈帧的结束位置。
- rbp (Base Pointer): 这指向栈的底部,通常用来作为参考点,便于访问栈帧中的局部变量和参数。
图中还提到了两个术语:
- Function Prologue: 这是函数开始执行时的一段代码,用于设置栈帧,例如保存旧的rbp值,分配局部变量所需的空间。
- Function Epilogue: 这是函数即将返回前的一段代码,用于恢复栈的状态,比如将rbp恢复到调用前的值。
另外,有注释说明[rbp] = old rbp (caller rbp)和[rbp + 0x8] = Return Address,这说明在栈中通过基指针rbp可以访问到调用者的基指针和返回地址。这对于理解函数如何返回到调用它的地方以及如何维护栈的结构非常重要。
Canary
为什么第一个字节是 0?
堆栈金丝雀(Stack Canary)是一种用于检测和防止堆栈缓冲区溢出攻击的安全特性。它的名称来源于矿工用金丝雀来检测有毒气体的做法;同理,堆栈金丝雀用来检测堆栈中的异常变化。当函数执行时,系统会在堆栈中的返回地址之前放置一个随机的金丝雀值。当函数准备返回时,会检查这个金丝雀值是否发生变化——如果金丝雀值被改变,系统就认为发生了缓冲区溢出,程序可以采取措施立即终止,从而阻止攻击的进一步发展。
金丝雀值的第一个字节通常是0(空字节)。这是因为在C语言中,字符串以空字符结束。如果溢出攻击尝试使用字符串操作来覆盖堆栈,并且没有包含空字节,它将在达到金丝雀的空字节时停止,因此可以保护剩余的金丝雀值和返回地址不被覆盖。这就增加了攻击者利用缓冲区溢出的难度,因为攻击者必须找到一种方法,在不触动金丝雀值的情况下覆盖返回地址。
堆栈金丝雀在性能和安全性之间提供了一种平衡,因为它们在函数返回之前引入了额外的检查,但与它们提供的安全好处相比,这种开销通常是微不足道的。它们是由编译器实现的,可以通过特定的编译器标志启用,例如在GCC中使用-fstack-protector,它为容易受到攻击的函数添加了堆栈保护。
PWN overflow
利用溢出(Overflow)的漏洞的原理是超出了程序为其数据所分配的内存区域的边界。在程序编写时,如果没有对输入数据进行恰当的边界检查,就可能出现超出边界的情况。这意味着当数据写入该区时,超出该区大小的数据可能会覆盖相邻内存位置的内容。
具体的溢出情况有以下几种:
- Buffer Overflow(缓冲区溢出): 当程序试图往缓冲区内写入超过其容量的数据时,就会发生缓冲区溢出。
- Stack Overflow(栈溢出): 类似于缓冲区溢出,但是是发生在调用栈的内存区域,通常是因为递归调用过深或是局部变量太大。
- Heap Overflow(堆溢出): 当程序往堆内存区域写入数据超过了为某个对象分配的空间时发生。
以缓冲区溢出举例,这种溢出漏洞的利用通常涉及以下几个步骤:
- 定位漏洞: 首先,攻击者需要识别出程序中的缓冲区溢出漏洞。
- 控制EIP: 接着,攻击者会尝试通过输入超出预期长度的数据来覆盖内存中的特定地址。这通常是指向所谓的指令指针(Instruction Pointer,IP),在x86架构下是
EIP(Extended Instruction Pointer),它决定了程序接下来要执行哪条指令。 - 注入代码: 攻击者可能会向溢出的缓冲区中注入恶意代码。这通常是一段小型的代码,称为shellcode,它通常用于提供攻击者访问系统的shell。
- 执行代码: 通过控制EIP,攻击者将其指向溢出缓冲区中的shellcode,当程序执行到这里时,会跳转到shellcode并执行。



