笔者的一个项目需要收集小红书|抖音|微博等平台上关于杭州的花景的数据集以进行语义分析训练模型。
在 Github 上看到一个 Star数高达 10K+的爬虫项目,遂在其基础上二次开发以便在自己的项目上使用,并提交了 PR 。
Repository
https://github.com/NanmiCoder/MediaCrawler
Contributions
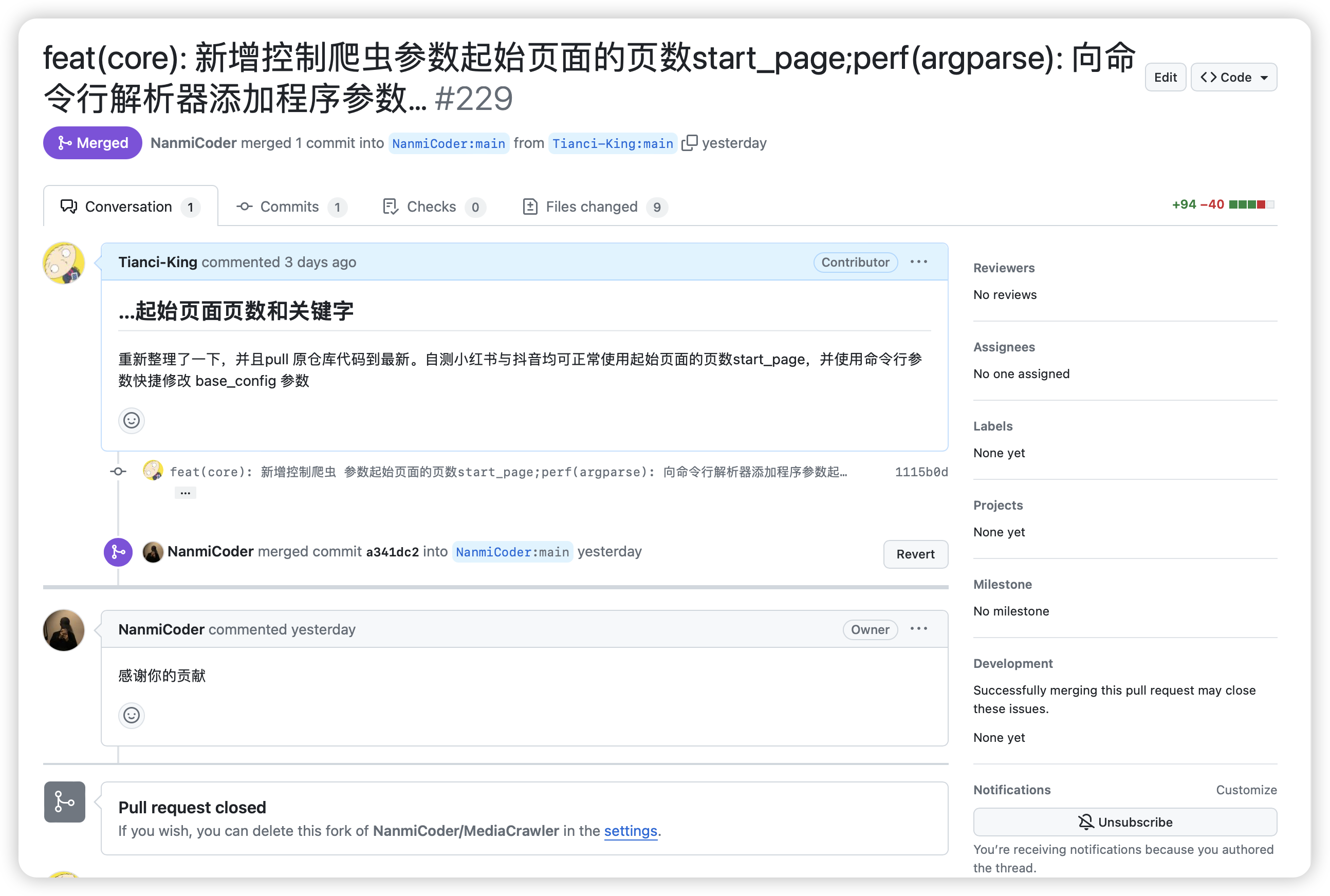
- feat(core): 新增控制爬虫
search参数起始页面的页数start_page,原项目固定只能从第一页开始爬取,不方便爬取时间跨度更大的内容信息。
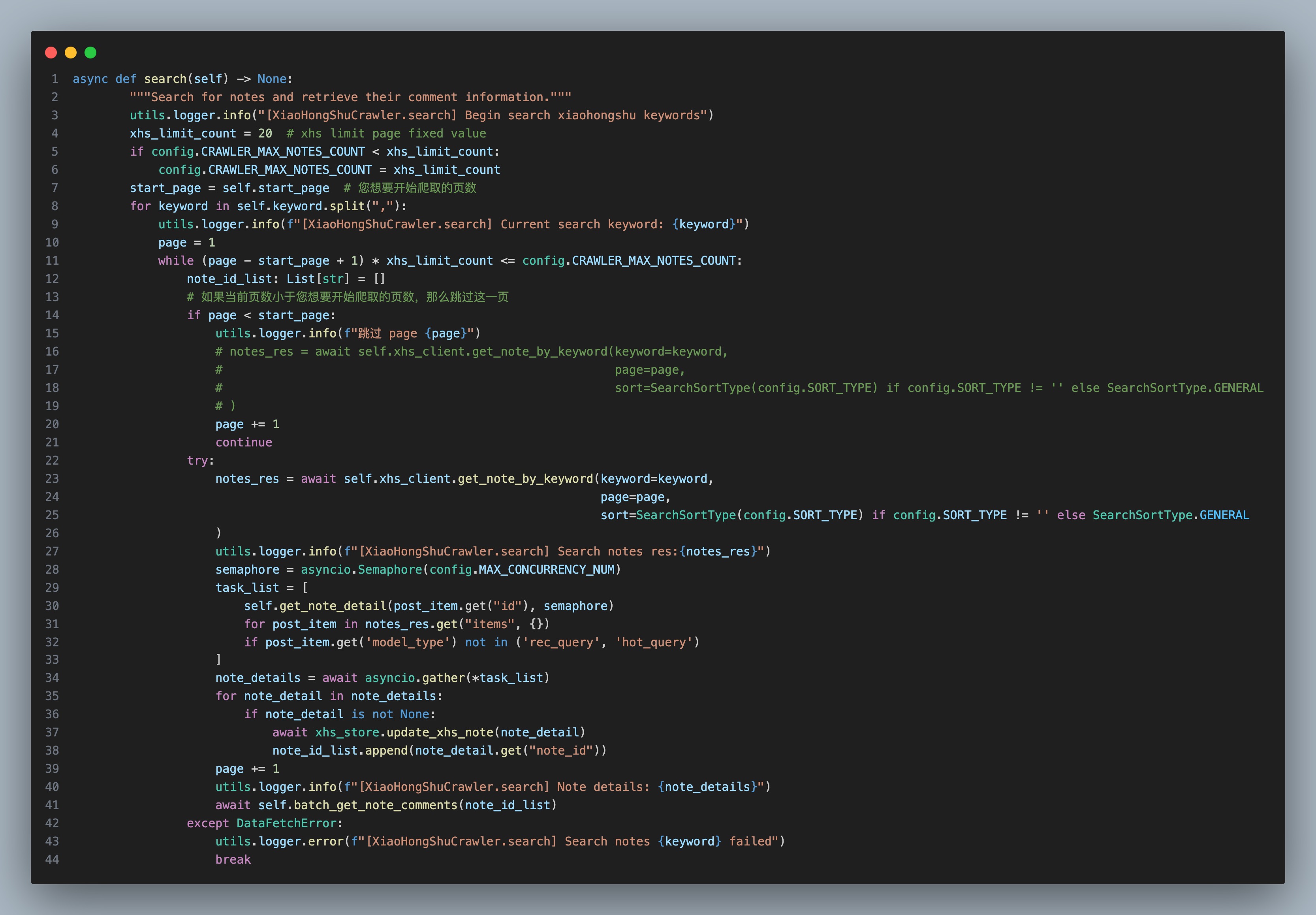
- perf(argparse): 向命令行解析器添加程序参数起始页面页数和关键字
原项目的命令行解析器程序参数提供的比较少,新增了 start_page 和 keyword 接口直接在命令行填写,方便后续编写 shell 脚本自动化爬取需求,原本需要前往 base_config 手动修改参数,现在可以直接在命令行上调整起始页面和查询关键字。
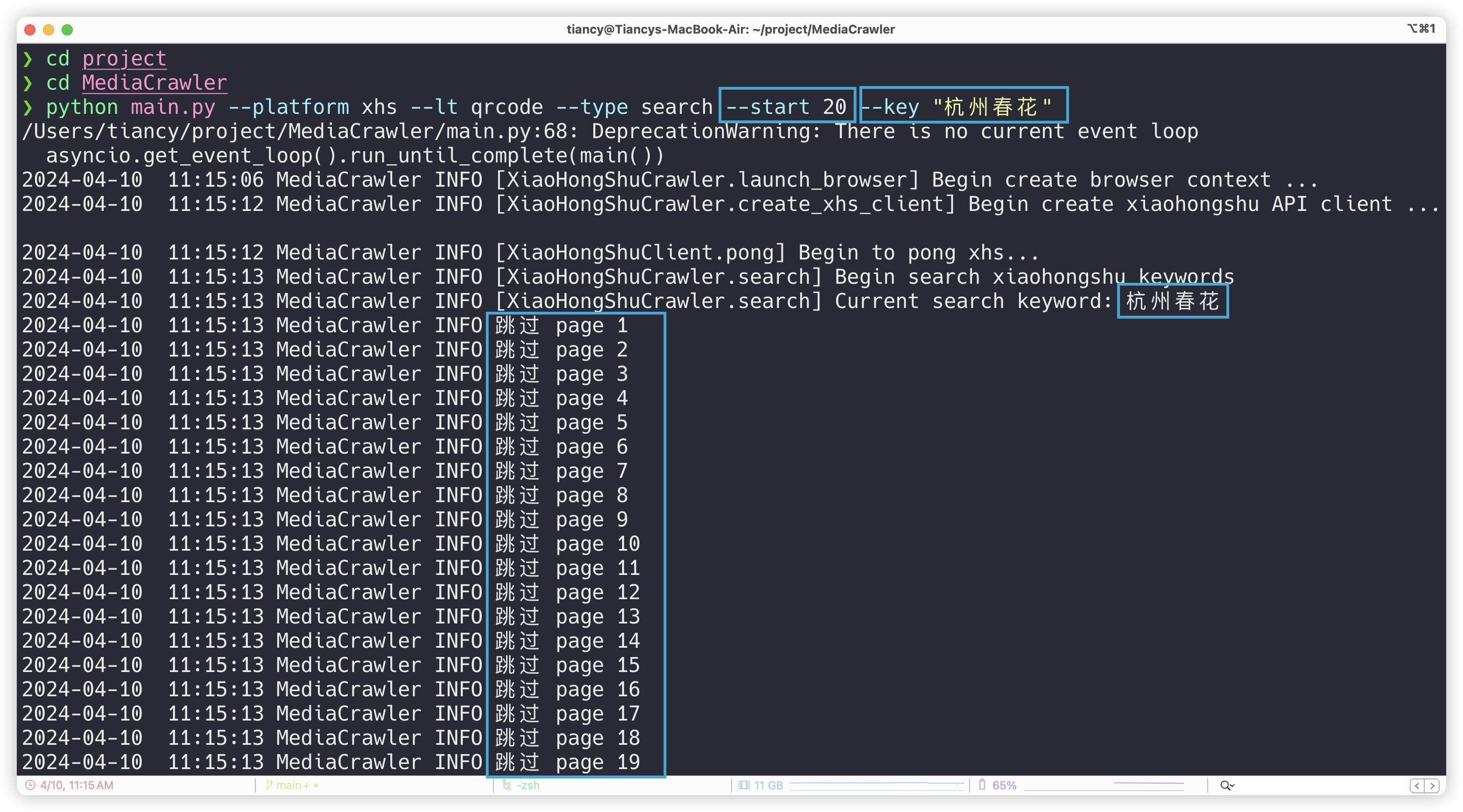
通过上述改写源码,爬取了杭州春天花景的”最热门”的200 多条数据,以及最新的 2024 年 3 月至 4 月的200 多条数据,圆满完成任务,并提交了 PR。